MODL: Massive Online Dictionary Learning

![]()
This python package (webpage) allows to perform sparse / dense matrix factorization on fully-observed/missing data very efficiently, by leveraging random subsampling with online learning. It is able to factorize matrices of terabyte scale with hundreds of components in the latent space in a few hours.
The stochastic-subsampled online matrix factorization (SOMF) algorithm is an order or magnitude faster than online matrix factorization (OMF) on large datasets.
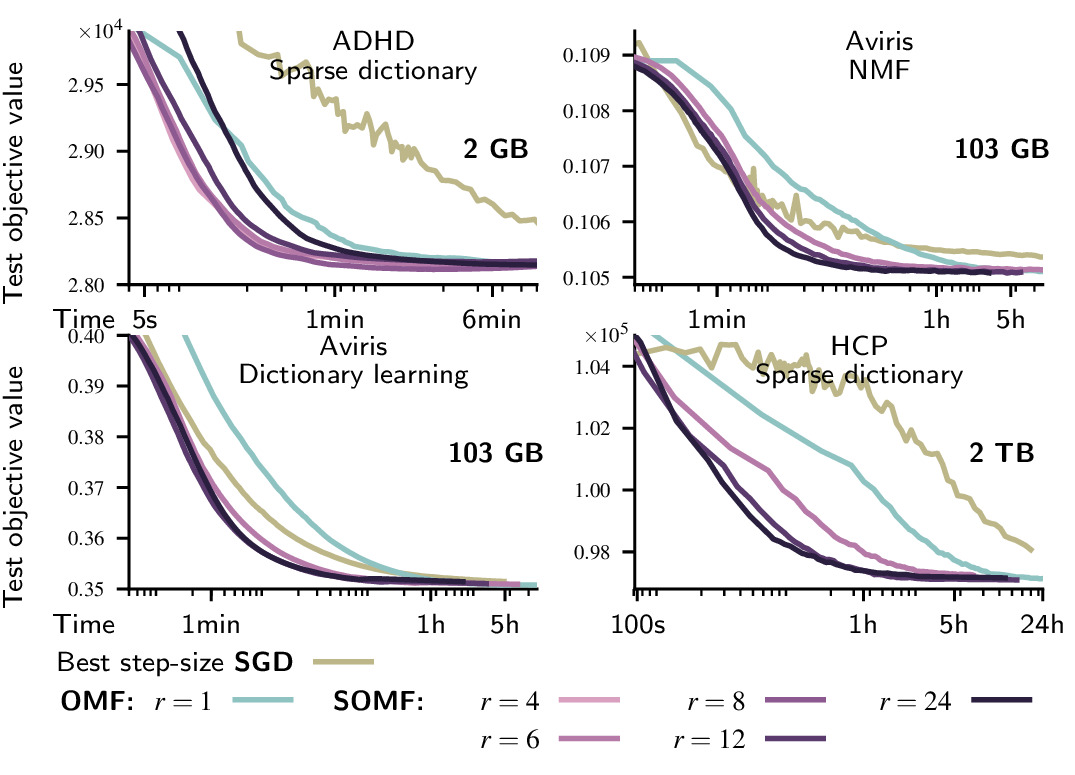
It provides scikit-learn compatible estimators that fully implements the stochastic-subsampled online matrix factorization (SOMF) algorithms. This package allows to reproduce the experiments and figures from the papers cited in reference.
Installing from source with pip
Installation from source is simple. In a command prompt:
git clone https://github.com/arthurmensch/modl.git
cd modl
pip install -r requirements.txt
pip install .
cd $HOME
py.test --pyargs modl
This package is only tested with Python 3.5+ !
Core code
The package essentially provides three estimators:
DictFact, that computes a matrix factorization from Numpy arraysfMRIDictFact, that computes sparse spatial maps from fMRI imagesImageDictFact, that computes a patch dictionary from an imageRecsysDictFact, that allows to predict score from a collaborative filtering approach
Examples
fMRI decomposition
A fast running example that decomposes a small dataset of resting-fmri data into a 70 components map is provided
python examples/decompose_fmri.py
It can be adapted for running on the 2TB HCP dataset, by changing the source parameter into ‘hcp’ (you will need to download the data first)
Hyperspectral images
A fast running example that extracts the patches of a HD image can be run from
python examples/decompose_image.py
It can be adapted to run on AVIRIS data, changing the image source into ‘aviris’ in the file.
Recommender systems
Our core algorithm can be run to perform collaborative filtering very efficiently:
python examples/recsys_compare.py
You will need to download datasets beforehand:
make download-movielens1m
make download-movielens10m
Contributions
Please feel free to report any issue and propose improvements on github.
References
This package implements the two following papers:
Arthur Mensch, Julien Mairal, Bertrand Thirion, Gaël Varoquaux. Stochastic Subsampling for Factorizing Huge Matrices, in IEEE Transactions on Signal Processing, 2018
Arthur Mensch, Julien Mairal, Bertrand Thirion, Gaël Varoquaux. Dictionary Learning for Massive Matrix Factorization, in Proceedings of the International Conference on Machine Learning, 2016
Related projects
- spira is a python library to perform collaborative filtering based on coordinate descent. It serves as the baseline for recsys experiments - we hard included it for simplicity.
- scikit-learn is a python library for machine learning. It serves as the basis of this project.
- nilearn is a neuro-imaging library that we wrap in our fMRI related estimators.
- cogspaces uses the dictionaries learned on large fMRI datasets to perform multi-study decoding.
Authors
Licensed under simplified BSD.
Arthur Mensch, 2015 - present